问题描述
积分排名在很多项目都会出现,积分排名主要满足以下需求:
- 查询用户名次。
- 查询TopN(即查询前N名的用户)
- 实时排名(很多项目是可选的)
当排序的数据量不大的时候,这个需求很容易满足,但是如果数据量很大的时候比如百万级、千万级甚至上亿的时候,或者有实时排名需求;这个时候要满足性能、低成本等需求,在设计上就变得复杂起来了。
解决方案
高效做法是不对积分进行排序,仅仅是统计每个积分区间的人数,用积分区间的形式去统计相应的人数,下面是算法描述。
1. 根据积分范围创建平衡二叉树
设[0, N]为积分范围, 构造的平衡二叉树如下图:

每个节点包含两个数据字段(除了指针):
- Range: 表示积分范围。
- Counts: 表示当前积分区间包含多少人。
积分的区间的划分是根据平分的方式,把当前积分范围一分为二生成两个子节点,然后递归的重复该步骤,直到积分区间无法划分为止(即区间[x, y], x == y)
例子:
假设积分范围为: [0, 5], 构造的平衡二叉树如下图:
节点内的数据表示当前积分区间的人数。
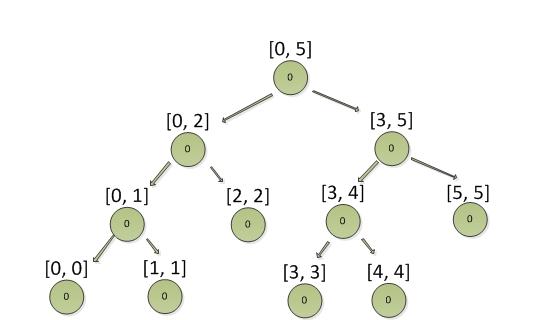
从上图可以看出来,所有积分都在叶子节点,叶子节点即最小粒度的积分区间。
2. 统计相应积分区间的人数
这里主要有两种操作:
假设积分为i,
添加积分:
添加积分的过程就是查找积分i, 同时累加查找过程经过的节点计数。
下面给出操作例子,注意观察操作路径。
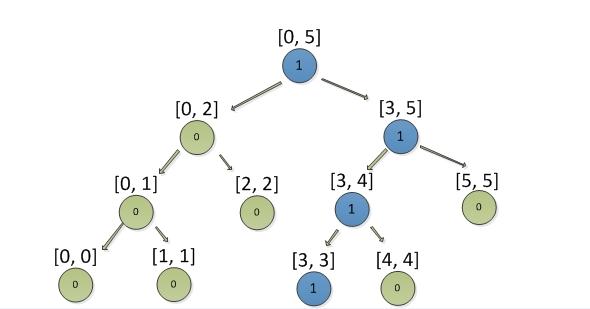
例: 需要添加积分3, 结果如下图
接着在添加积分4,结果如下图
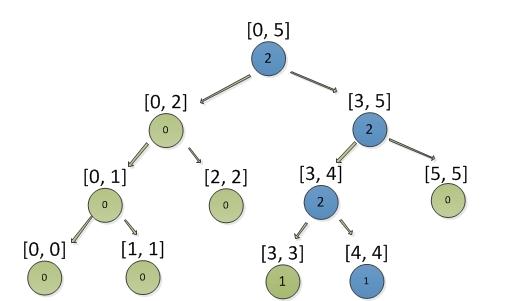
接着再添加积分4,结果如下图
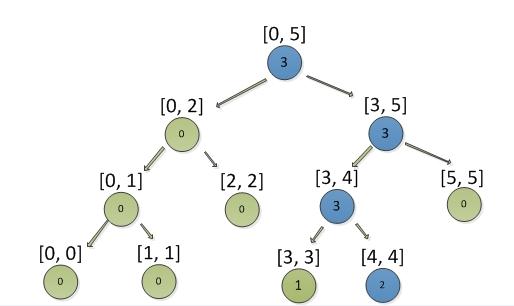
接着添加积分2,结果如下图
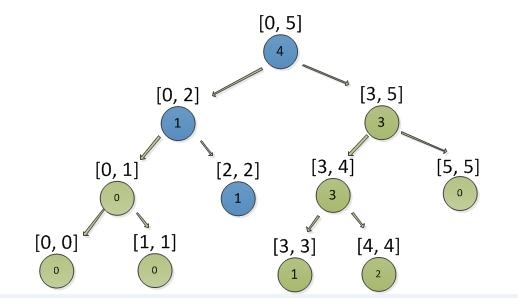
删除积分
删除积分的过程也是查找积分i, 区别是查找过程经过的节点计数全部减1。
Ps: 只有积分是存在的情况下,才能做删除操作,另外用一组标记,标识积分是否存在,这里就不列举了。
例子: 删除积分4, 结果如下图
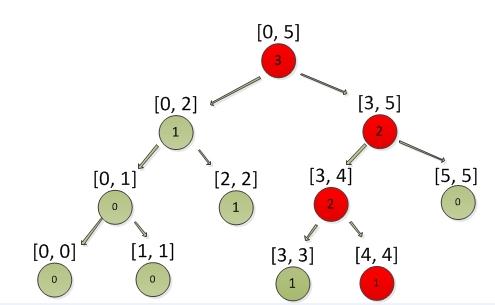
3. 查询名次操作
查询某个积分的排名的过程也是查找积分i的过程,下面是查找过程统计节点计数的算法:
对于查找路径上的任意节点,如果积分在左节点区间,则累加右节点区间的计数。
最终累加计数的结果加1即是积分的名次
例子: 查找积分3的名次
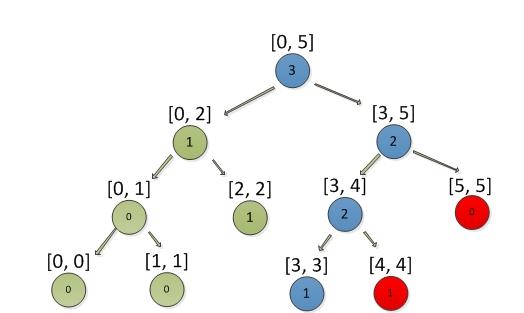
蓝色节点是查找积分3经过的路径,红色节点是需要累加的计数值。
最终结果是:0 + 1 + 1, 积分3的名次是第2名
从上面的算法可以看出,对平衡二叉树的操作,算法复杂度是O(log N), N是最大积分。
在积分范围不变的情况下,算法复杂度是稳定的,跟用户量无关,因此可以实现海量用户积分排名、实时排名算法需要。
对于海量积分数据实时排名、这里给出的是核心算法,实际业务的时候还需要增加一些额外的处理,比如uid于积分的映射表用于记录用户历史积分、积分与uid的映射表用于TopN这种查询前N名的需求、数据持久化、高可用等需求。
参考自